
Python模块解析 - SimpleHTTPServer和BaseHTTPServer模块
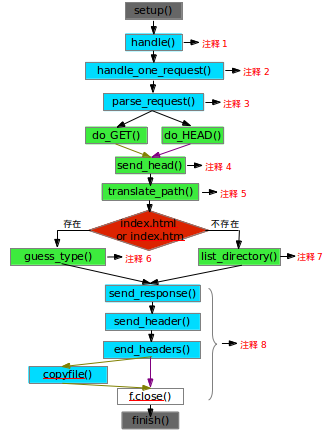
前面有学习了SocketServer模块,之前说过SocketServer算是最基本的python服务器框架,那本文讲的BaseHTTPServer模块就是基于SocketServer,而SimpleHTTPServer模块则是基于BaseHTTPServer模块,所以他们的继承关系就很明了了.本文还是会以一个小栗子开始,结合类继承图和程式执行过程图来学习原码.
注:本文基于python2.7,不同的版本可能会导致差异.
类的继承关系和执行流程
图中用不同颜色来划分不同类的方法,有方法重写的部分则是将该方法归于重写方法的类.

举个栗子
1 | import SocketServer |
相比之前SocketServer模块中的栗子,是不是更为简洁.其实这里只是将request的处理交给了SimpleHTTPRequestHandler.主体的执行流程已经在上图给出.之前的部分请参照SocketServer模块.那下面我们就对流程图中需要说明的地方进行解释,依执行流程图注释顺序开始.
注释1 - handle():
handle算是入口吧,我们之前是在自己写的Handler类中重写了handle方法,这里也一样.重写了最基本的类BaseRequestHandler中的handle方法.
需要注意的是close_connection这个变量,它主要的作用是后面判断request的Connection,判断客户端到服务器端的连接是否持续有效,如果是Keep-Alive,当出现对服务器的后继请求时,就能避免了建立或者重新建立连接.
注释2 - handle_one_request():
handle_one_request最重要的工作就是1
self.raw_requestline = self.rfile.readline(65537)
其实就是读取客户端来的request,然后将得到的request让parse_request做解析,并且根据parse_request的解析结果调用对应的处理方法(GET或HEAD,SimpleHTTPServer只支持GET和HEAD方法,不支持POST等其它的方法).
需要注意的地方:1
2
3
4
5mname = 'do_' + self.command
if not hasattr(self, mname):
self.send_error(501, "Unsupported method (%r)" % self.command)
return
method = getattr(self, mname)
getattr(x, y)的用法其实就可以理解为x.y,所以这里的意思就是调用self.mname()
注释3 - parse_request():
对request的解析,得到后面需要的command(GET or HEAD), path(请求的url), version(HTTP version),并对version进行基本的版本检查.
需要注意的是:1
2
3
4
5
6
7elif len(words) == 2:
command, path = words
self.close_connection = 1
if command != 'GET':
self.send_error(400,
"Bad HTTP/0.9 request type (%r)" % command)
return False
这其实是BaseHTTPServer对HTTP/0.9版本的判断.因为HTTP/0.9版本只支持GET方法,所以这一段就明白了吧!parse_request的最后是对request Connection的判断,判断此连接是否为持续连接.
注释4 - send_head():
send_head是两种方法(GET HEAD)都要执行的部分(其实本身GET和HEAD两中方法就差不多,只不过HEAD只是头信息的交流),这也是SimpleHTTPServer的整个执行过程了.1
2
3
4
5
6
7
8
9
10
11
12
13
14if os.path.isdir(path):
if not self.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(301)
self.send_header("Location", self.path + "/")
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
调用translate_path,根据其返回的路径判断是否为目录.
如果是目录,若在该目录下能找到index.html或者index.htm文件,则返回的信息的正文是index.html的内容,若没有发现index.html相关的文件,则调用list_directory方法,返回给客户端的信息的正文则是当前目录下的所有文件链接.
如果不是目录是文件,则直接返回文件内容.
后面的是调用guess_type得到头信息中的Content-type内容.
剩下的部分就是完善回复的头信息了,如Content-Length,Last-Modified的信息.
需要注意的是for..else这样的结构,他的逻辑是:for循环中,如果到结束都没有任何一个从break中退出,那么执行和for对应的else,只要有从break中退出,则else部分不执行.
注释5 - translate_path():
这部分就是解析path,找到对应本地的文件目录或者文件路径.
注释6 - guess_type():
返回类似于type/subtype格式的Content-type内容.
注释7 - list_directory():
这个是当没有找到index.html或者index.htm文件的时候,模块默认是将当前路径下的所有文件展示出来.1
2
3
4
5
6
7
8
9
10
11
12for name in list:
fullname = os.path.join(path, name)
displayname = linkname = name
# Append / for directories or @ for symbolic links
if os.path.isdir(fullname):
displayname = name + "/"
linkname = name + "/"
if os.path.islink(fullname):
displayname = name + "@"
# Note: a link to a directory displays with @ and links with /
f.write('<li><a href="%s">%s</a>\n'
% (urllib.quote(linkname), cgi.escape(displayname)))
他给当前目录下的所有文件建立相应的链接,当在客户端点击相应的文件名时,就会产生对server的一次访问,server会根据文件的链接返回对应文件的内容.
注释8:
这部分就很简单了,用self.wfile.writ的方法完善状态行,头信息.有一点在end_headers中,因为HTTP/0.9和HTTP/1.1的差异,所以在HTTP/1.1的版本中需要在头信息和正文之间加一个空行.
剩下的还有一个GET专有的方法.1
2def copyfile(self, source, outputfile):
shutil.copyfileobj(source, outputfile)
这其实就是在send_head之后,返回给客户端的头信息和状态行都已经ok了,唯独缺少的是正文的信息了.所以这里做的也就是通过send_head返回的文件修饰符,将正文内容copy到self.wfile中.
结语
至于后面的close和finish方法都是最后的收尾工作
可以看到,其实SimpleHTTPServer能帮助我们做很多事情,而且他将内容和服务器逻辑分开,所以每次更新的时候就不用停掉服务器了.
That’s all,Thank you
